We have some news on the popular bloodborne , after some gpu fixes bloodborne works much better now , characters are display correctly and there are a few fixes in stability 🙂
 1
1
News
Patches and cheats support
One of our contributors , Daniel , added support for cheats and patches on shadps4 latest WIP version.
Cheats
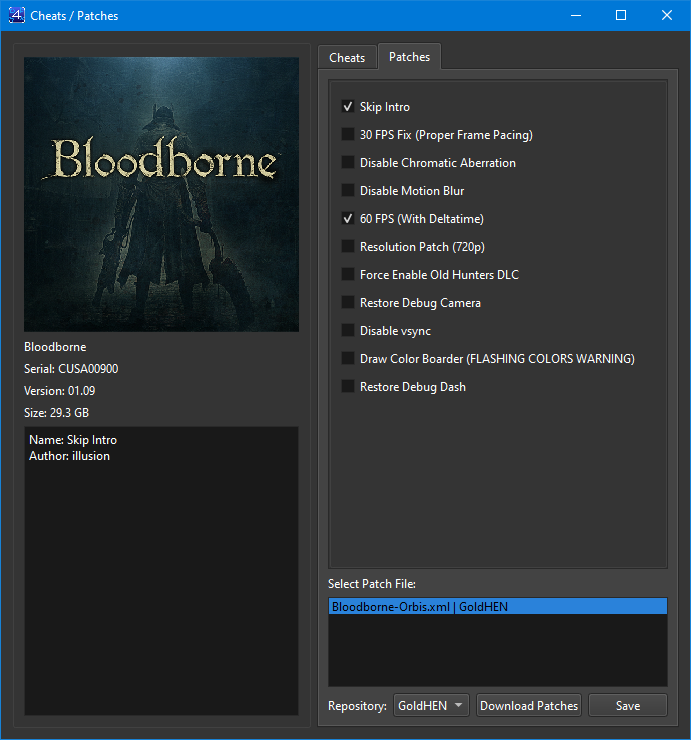
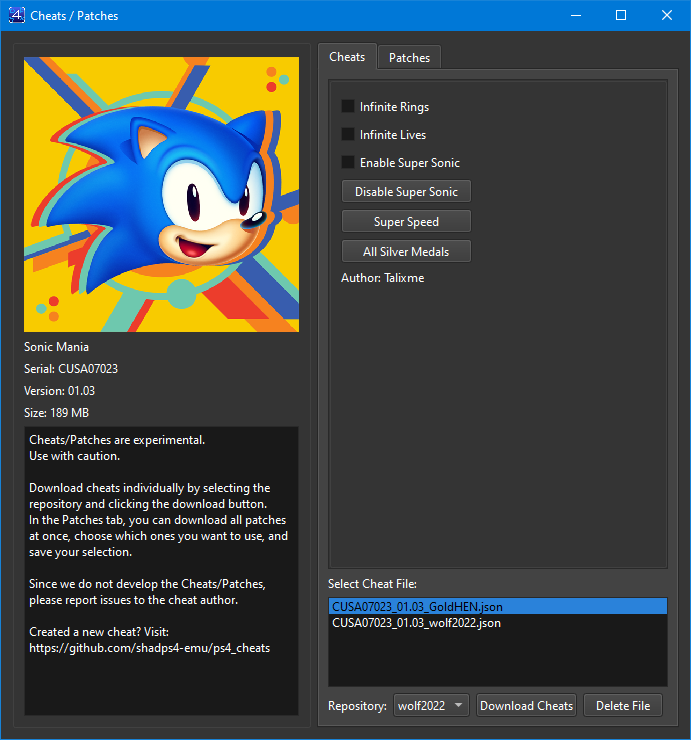
Right-click on a game and select the ‘Cheats/Patches’ option. From there, you can download cheats from three repositories: wolf2022, GoldHEN, and shadPS4. If a cheat is available in more than one repository, you can delete the undesired file using a specific button. Cheats will only be downloaded for the specific serial and version of the installed game and will be renamed with the format serial+version+repository.
In the top menu, under “Settings -> Utils -> Download Cheats/Patches”, you can download all cheats at once for the installed games. It is recommended to apply cheats only during gameplay.
Patches
In addition to cheats, you can also download patches. Unlike cheats, patches are downloaded for all games, not just one specific game. The patch file is quite small. Right-click on a game, select ‘Cheats/Patches’, go to the patches tab, check the patches you want to use, and click ‘Save’. This ensures that these options will be applied automatically every time the emulator is started, without needing to reopen the panel. In the Patches tab, if you hover over them you can see the description on the left side.

News
Rock Band 4
This time we talk about rock band 4 , a rythym game that works kind on shadps4. Still need some hacks applied (like bloodborne does) but as you can see from above video it is quite smooth.

News
Blazblue Cross Tag Battle
This game seems to be almost full playable in shadps4 v0.2.1 . Enjoy 🙂
 1
1
News
Bloodborne ingame video
One more time , bloodborne. Although we still need some hacks for getting bloodborne work , we work towards that to have the fixed shortly. Below you can see a video from ingame , we some latest additions we made it even faster that the one we posted few days ago.
News
Even more bloodborne progress
As you can figure out bloodborne progress changes rapidaly fast. Using turtle’s pr https://github.com/shadps4-emu/shadPS4/pull/465 you can now even get ingame in bloodborne. Currently it is a nasty hack but it will be implemented properly in future versions . A video below shows the current status using that *hacks*
News
More Bloodborne progress
After the release that came out just yesterday , we have more exciting news for you . This time one of our contributors , Roamic finished his Avplayer pull request and fixed some sound bugs as well and bloodborne is now capable to play it’s videos. Still lot work is left but it is a step to the right direction.

Releases
Shadps4 v0.2.0 just dropped
A new release v0.2.0 codename validptr just dropped. There are excitement new features in this release (also you will find that Red dead redemption , Dark souls , bloodborne has some updated status on this release).
You can download the new release from download page.
A short description of changes :
- Adding macOS support
- Big shader recompiler improvements
- Core improvements
- GUI improvements
And A large one 😀
What’s Changed
- shader_recompiler: Implement most integer image atomics, workgroup barriers and shared memory load/store by @raphaelthegreat in https://github.com/shadps4-emu/shadPS4/pull/231
- Recompiler: sampler patching by @psucien in https://github.com/shadps4-emu/shadPS4/pull/236
- Fix ShowSplash size by @DanielSvoboda in https://github.com/shadps4-emu/shadPS4/pull/235
- Misc Fixes by @georgemoralis in https://github.com/shadps4-emu/shadPS4/pull/233
- shader_recompiler: Check usage before enabling capabilities by @raphaelthegreat in https://github.com/shadps4-emu/shadPS4/pull/245
- CMakeLists.txt cleanup by @Xphalnos in https://github.com/shadps4-emu/shadPS4/pull/244
- Misc fixes 3 by @georgemoralis in https://github.com/shadps4-emu/shadPS4/pull/239
- Create shortcut by @DanielSvoboda in https://github.com/shadps4-emu/shadPS4/pull/246
- fix linux again by @DanielSvoboda in https://github.com/shadps4-emu/shadPS4/pull/254
- Graphics: missing features and fixes by @psucien in https://github.com/shadps4-emu/shadPS4/pull/253
- Eliminate compiler warning by @OFFTKP in https://github.com/shadps4-emu/shadPS4/pull/264
- Fix sceAudioOutOpen not handling audio param attributes by @viniciuslrangel in https://github.com/shadps4-emu/shadPS4/pull/267
- Added Legacy Min/Max ops by @ItsStolas in https://github.com/shadps4-emu/shadPS4/pull/266
- Update building-linux.md with full instructions by @BigTreezZ in https://github.com/shadps4-emu/shadPS4/pull/260
- Improve physical device selection in Vulkan renderer by @viniciuslrangel in https://github.com/shadps4-emu/shadPS4/pull/247
- add V_MAD_U32_U24 by @DanielSvoboda in https://github.com/shadps4-emu/shadPS4/pull/262
- fix shortcut name with unaccepted characters by @DanielSvoboda in https://github.com/shadps4-emu/shadPS4/pull/269
- impl V_CMP_CLASS_F32 common filter masks by @viniciuslrangel in https://github.com/shadps4-emu/shadPS4/pull/276
- Update building-linux.md with thread numbers by @BigTreezZ in https://github.com/shadps4-emu/shadPS4/pull/275
- More HLE stuff and fixes by @georgemoralis in https://github.com/shadps4-emu/shadPS4/pull/273
- Adding Bloodborne screenshot by @Xphalnos in https://github.com/shadps4-emu/shadPS4/pull/278
- HR Timers support and event queue refactoring by @psucien in https://github.com/shadps4-emu/shadPS4/pull/277
- Filesystem errors and Base Array Layers by @vladmikhalin in https://github.com/shadps4-emu/shadPS4/pull/280
- Misc implementations and fixes. by @polybiusproxy in https://github.com/shadps4-emu/shadPS4/pull/250
- Update CMakeLists.txt to fix compilation error by @BigTreezZ in https://github.com/shadps4-emu/shadPS4/pull/282
- Fixed an issue with number of components of shader attributes by @vladmikhalin in https://github.com/shadps4-emu/shadPS4/pull/283
- Fix Linux builds by @polybiusproxy in https://github.com/shadps4-emu/shadPS4/pull/284
- shader_recompiler/frontend: Implement opcodes by @polybiusproxy in https://github.com/shadps4-emu/shadPS4/pull/289
- Missing graphics features for flOw & Flower by @psucien in https://github.com/shadps4-emu/shadPS4/pull/292
- Fix pthread deprecation warnings by @jas0n098 in https://github.com/shadps4-emu/shadPS4/pull/290
- gnmdriver: Implement shader functions by @polybiusproxy in https://github.com/shadps4-emu/shadPS4/pull/287
- Various linux fixes by @raphaelthegreat in https://github.com/shadps4-emu/shadPS4/pull/293
- Return EBUSY from sceKernelPollEventFlag instead of ETIMEDOUT. by @squidbus in https://github.com/shadps4-emu/shadPS4/pull/299
- Implemented load_buffer_format_* conversions by @vladmikhalin in https://github.com/shadps4-emu/shadPS4/pull/295
- Move “game_data” to RW directory inside user folder for linux by @qurious-pixel in https://github.com/shadps4-emu/shadPS4/pull/252
- code: Fixup some regressions by @raphaelthegreat in https://github.com/shadps4-emu/shadPS4/pull/300
- kernel: Implement posix_pthread_once by @dima-xd in https://github.com/shadps4-emu/shadPS4/pull/297
- Fixed buffer_store_* regression by @vladmikhalin in https://github.com/shadps4-emu/shadPS4/pull/302
- Misc Fixes (forgot the number) by @georgemoralis in https://github.com/shadps4-emu/shadPS4/pull/281
- spirv: Address some regressions in buffer loads by @raphaelthegreat in https://github.com/shadps4-emu/shadPS4/pull/304
- Surface management rework (1/3) by @psucien in https://github.com/shadps4-emu/shadPS4/pull/307
- vk_scheduler: Add api for defering operations by @raphaelthegreat in https://github.com/shadps4-emu/shadPS4/pull/311
- Add macOS support by @squidbus in https://github.com/shadps4-emu/shadPS4/pull/294
- Add sceKernelGetDirectMemoryType, update sceKernelReserveVirtualRange by @Borchev in https://github.com/shadps4-emu/shadPS4/pull/312
- Replace remaining uses of
QDir::currentPath() / "user"withGetUserPath(UserDir). by @squidbus in https://github.com/shadps4-emu/shadPS4/pull/314 - docs: Syntax highlighting for the example code by @noxifoxi in https://github.com/shadps4-emu/shadPS4/pull/316
- Fix macOS builds by @VasylBaran in https://github.com/shadps4-emu/shadPS4/pull/317
- Install x86_64 MoltenVK from Homebrew. by @squidbus in https://github.com/shadps4-emu/shadPS4/pull/318
- Fixed the button- PKG patch version is older by @DanielSvoboda in https://github.com/shadps4-emu/shadPS4/pull/319
- address_space: Fix windows placeholder mapping by @raphaelthegreat in https://github.com/shadps4-emu/shadPS4/pull/323
- memory: Cleanups and refactors by @raphaelthegreat in https://github.com/shadps4-emu/shadPS4/pull/324
- Misc Fixes 7 by @raziel1000 in https://github.com/shadps4-emu/shadPS4/pull/320
- BUFFER_STORE_DWORDX2 by @DanielSvoboda in https://github.com/shadps4-emu/shadPS4/pull/325
- semaphore: Yet another race condition fix by @raphaelthegreat in https://github.com/shadps4-emu/shadPS4/pull/327
- 64 bits OP, impl V_ADDC_U32 & V_MAD_U64_U32 by @viniciuslrangel in https://github.com/shadps4-emu/shadPS4/pull/310
- fix tls patch on windows by @viniciuslrangel in https://github.com/shadps4-emu/shadPS4/pull/328
- Move presentation to separate thread/improve sync by @raphaelthegreat in https://github.com/shadps4-emu/shadPS4/pull/303
- Surface management rework (2/3) by @psucien in https://github.com/shadps4-emu/shadPS4/pull/329
- log improvement ThrowInvalidType by @DanielSvoboda in https://github.com/shadps4-emu/shadPS4/pull/330
- Implement some pthread calls by @dima-xd in https://github.com/shadps4-emu/shadPS4/pull/332
- Fixup for detiler artifacts on macOS by @VasylBaran in https://github.com/shadps4-emu/shadPS4/pull/335
- Add sem_timedwait polyfill for macOS. by @squidbus in https://github.com/shadps4-emu/shadPS4/pull/336
- kernel: Implement sceKernelSetVirtualRangeName by @georgemoralis in https://github.com/shadps4-emu/shadPS4/pull/338
- Fix SearchFree function bug by @Borchev in https://github.com/shadps4-emu/shadPS4/pull/339
- Don’t download unnecessary DLLs by @Xphalnos in https://github.com/shadps4-emu/shadPS4/pull/341
- Add pthread_attr_getstacksize thunk by @Borchev in https://github.com/shadps4-emu/shadPS4/pull/343
- shader_recompiler: Small instruction parsing refactor/bugfixes by @raphaelthegreat in https://github.com/shadps4-emu/shadPS4/pull/340
- Reorganization of includes by @Xphalnos in https://github.com/shadps4-emu/shadPS4/pull/348
- core: Implement sceRandomGetRandomNumber by @dima-xd in https://github.com/shadps4-emu/shadPS4/pull/350
- Adding macOS to readme + minor changes by @Xphalnos in https://github.com/shadps4-emu/shadPS4/pull/351
- SaveData Fixes by @raziel1000 in https://github.com/shadps4-emu/shadPS4/pull/346
- Added Git version info by @georgemoralis in https://github.com/shadps4-emu/shadPS4/pull/355
- Better logo for shadPS4 by @Xphalnos in https://github.com/shadps4-emu/shadPS4/pull/352
- Add macOS icon. by @squidbus in https://github.com/shadps4-emu/shadPS4/pull/356
- reuse: fix license for externals by @abouvier in https://github.com/shadps4-emu/shadPS4/pull/358
- Minor Qt GUI update by @Xphalnos in https://github.com/shadps4-emu/shadPS4/pull/363
- SampleCountFlagBits::e16 – GetGpuClock64 by @DanielSvoboda in https://github.com/shadps4-emu/shadPS4/pull/360
- add-SurfaceFormat by @DanielSvoboda in https://github.com/shadps4-emu/shadPS4/pull/365
- video_core: Minor fixes by @raphaelthegreat in https://github.com/shadps4-emu/shadPS4/pull/366
- video_core: Implement guest buffer manager by @raphaelthegreat in https://github.com/shadps4-emu/shadPS4/pull/373
- Workflows cleanup + misc fixes by @Xphalnos in https://github.com/shadps4-emu/shadPS4/pull/371
- qt_gui: Added double-click game icon to start game by @ElBread3 in https://github.com/shadps4-emu/shadPS4/pull/379
- qt_gui: Refreshing game list after install directory change by @SamuelFontes in https://github.com/shadps4-emu/shadPS4/pull/380
- 361: Game directory window appears every time by @SamuelFontes in https://github.com/shadps4-emu/shadPS4/pull/381
- revert some sdl switches by @georgemoralis in https://github.com/shadps4-emu/shadPS4/pull/382
- Kernel-Related Fixes by @StevenMiller123 in https://github.com/shadps4-emu/shadPS4/pull/386
- Update latest build instructions.md by @SleepingSnakezzz in https://github.com/shadps4-emu/shadPS4/pull/385
- Submodules updates + misc fixes by @georgemoralis in https://github.com/shadps4-emu/shadPS4/pull/368
- gui: Implement settings dialog by @dima-xd in https://github.com/shadps4-emu/shadPS4/pull/390
- Gnmdriver: More functions by @psucien in https://github.com/shadps4-emu/shadPS4/pull/410
- Video Core: debug tools by @psucien in https://github.com/shadps4-emu/shadPS4/pull/412
- Build stabilization by @psucien in https://github.com/shadps4-emu/shadPS4/pull/413
- Enable VK_EXT_robustness2 nullDescriptor only if supported. by @squidbus in https://github.com/shadps4-emu/shadPS4/pull/419
- Add partial unmap support by @Borchev in https://github.com/shadps4-emu/shadPS4/pull/322
- thread_management.cpp: Various Mandatory Threading Fixes | Resolve #398 by @lzardy in https://github.com/shadps4-emu/shadPS4/pull/394
- spirv: fix image sample lod/clamp/offset translation by @viniciuslrangel in https://github.com/shadps4-emu/shadPS4/pull/402
- video_core: Crucial buffer cache fixes + proper GPU clears by @raphaelthegreat in https://github.com/shadps4-emu/shadPS4/pull/414
- Fix some Vulkan validation errors on macOS. by @squidbus in https://github.com/shadps4-emu/shadPS4/pull/420
- Basic gamepad support through SDL by @counter185 in https://github.com/shadps4-emu/shadPS4/pull/407
- video_core: Various fixes by @raphaelthegreat in https://github.com/shadps4-emu/shadPS4/pull/423
- qt-gui: Added GPU device selection functionality by @SamuelFontes in https://github.com/shadps4-emu/shadPS4/pull/399
- video_core: CPU flip relay by @psucien in https://github.com/shadps4-emu/shadPS4/pull/415
- core/memory: Fix error on virtual queries of reserved regions by @polybiusproxy in https://github.com/shadps4-emu/shadPS4/pull/429
- spirv: Simplify shared memory handling by @raphaelthegreat in https://github.com/shadps4-emu/shadPS4/pull/427
- scePthreadAttrSetstack implementation by @StevenMiller123 in https://github.com/shadps4-emu/shadPS4/pull/391
- core: misc changes by @dima-xd in https://github.com/shadps4-emu/shadPS4/pull/430
- shader_recompiler: basic implementation of
BUFFER_STORE_FORMAT_by @psucien in https://github.com/shadps4-emu/shadPS4/pull/431 - Ability to change username by @Xphalnos in https://github.com/shadps4-emu/shadPS4/pull/432
- Qt-GUI: Adding User Name selection by @Xphalnos in https://github.com/shadps4-emu/shadPS4/pull/440
- gpu: handle primitive restart index register by @viniciuslrangel in https://github.com/shadps4-emu/shadPS4/pull/438
- Qt-GUI: Cleaning the option menu by @Xphalnos in https://github.com/shadps4-emu/shadPS4/pull/443
New Contributors
- @DanielSvoboda made their first contribution in https://github.com/shadps4-emu/shadPS4/pull/235
- @viniciuslrangel made their first contribution in https://github.com/shadps4-emu/shadPS4/pull/267
- @ItsStolas made their first contribution in https://github.com/shadps4-emu/shadPS4/pull/266
- @BigTreezZ made their first contribution in https://github.com/shadps4-emu/shadPS4/pull/260
- @vladmikhalin made their first contribution in https://github.com/shadps4-emu/shadPS4/pull/280
- @polybiusproxy made their first contribution in https://github.com/shadps4-emu/shadPS4/pull/250
- @jas0n098 made their first contribution in https://github.com/shadps4-emu/shadPS4/pull/290
- @squidbus made their first contribution in https://github.com/shadps4-emu/shadPS4/pull/299
- @dima-xd made their first contribution in https://github.com/shadps4-emu/shadPS4/pull/297
- @Borchev made their first contribution in https://github.com/shadps4-emu/shadPS4/pull/312
- @noxifoxi made their first contribution in https://github.com/shadps4-emu/shadPS4/pull/316
- @VasylBaran made their first contribution in https://github.com/shadps4-emu/shadPS4/pull/317
- @ElBread3 made their first contribution in https://github.com/shadps4-emu/shadPS4/pull/379
- @SamuelFontes made their first contribution in https://github.com/shadps4-emu/shadPS4/pull/380
- @StevenMiller123 made their first contribution in https://github.com/shadps4-emu/shadPS4/pull/386
- @SleepingSnakezzz made their first contribution in https://github.com/shadps4-emu/shadPS4/pull/385
- @lzardy made their first contribution in https://github.com/shadps4-emu/shadPS4/pull/394
- @counter185 made their first contribution in https://github.com/shadps4-emu/shadPS4/pull/407
Full Changelog: https://github.com/shadps4-emu/shadPS4/compare/0.1.0…v.0.2.0
News
Bloodborne progress
As already probably figured out from the posts around , we continue to improve slowly but stable the bloodborne game. In this new video posted below we have Avplayer working (Avplayer is streaming library that plays mp4 files on ps4) , and some graphics improvements .
Still we are far from making this game playable (although Dark Souls that uses similar engine already has some ingame graphics) but we progressing slowly to give you more every day.
Stay tuned for more updates soon.

Developing
Implemented guest buffer manager
What problem does this solve
Up until this point main branch used a host memory stream buffer for making all resources accessible to the GPU. This is because AMD hardware has very small alignment requirements for both uniform and storage buffers (only 4 bytes) while nvidia has 64/16 respectively. The device local-host visible part of memory is also too small for most systems to serve this purpose, and we probably need it for better things.
This adds a ton of overhead to GPU emulation as all buffer bindings need to memcpy a (sometime large) chunk of memory to the stream buffer. It was also slow as GPU is not using VRAM for fast access. It also didn’t work for storage buffers where the writes would be lost, as there was no way of preserving them in the volatile buffer.
This PR aims to solve most of the these issues by keeping a GPU side mirror of guest address space for the GPU to access. It uses write protection to track any modifications and will re-sync the ranges on demand when needed. It’s still a bit incomplete though in ways I will cover more below. Seems to fix flicker on RDR with AMD gpus, but it still persists on NVIDIA which needs more investigation.
Basic design
In terms of operations the most important is searching for buffers as this is done multiple times per draw. Tracking page dirtiness must be fast as well. Insertion/deletion of buffers should also be fast but this happens more rarely than the other operations.
For page tracking we employ a bit-based tracker with 4KB granularity, same as the host page size we target. It works on 2 levels; each WordManager is responsible for tracking 4MB of virtual address space and is created on demand when a particular region is invalidated. The MemoryTracker will iterate each manager that touches the region and gather all dirty ranges from each one. All this uses bit operations and avoids heap allocations, so it’s quite fast compared to an interval set.
For the buffer cache, we cache buffers with host page size granularity. This makes things easier as we can avoid having to manage buffer overlaps; each page is exclusively owned by a buffer at a time. Buffers are stored in a multi level page table that covers (most) of the virtual address space and has comparable performance to a flat array access, but also using far less memory in the process. While at it, I’ve also switched the texture cache to use the same page table, as it should be faster than the existing hash map.
Every time we fetch a buffer, we check if the region is CPU dirty and build a list of copies needed to validate the buffer from CPU data. The data is copied to a staging buffer and the buffer is validated. I’ve added a small optimization in this area, specially for small uniform buffers whose page has not been gpu modified. For those we can skip cached path and directly copy data into device local-host visible stream buffer to avoid a potential renderpass break in games that update uniforms often. Buffer upload reordering is also a potential future optimization, but that will matter more on tiled GPUs I imagine.
GPU modification tracking is partially implemented. The switch to cached buffer objects also raises the issue of alignment again. An easy solution would be to force SSBOs in most cases but still has cases where alignment of 16 is not satisfied. Switching to device buffer address is also possible, but would probably result in performance degradation on NVIDIA hardware, as it has fixed function binding points for UBOs/SSBOs and hardware probably prefers you use them.
So on each buffer bind we check the offset and align it down if necessary, adding the offset into a push constant block that gets added into every buffer access. This results in a bit more overhead during each buffer access but I believe its the simplest approach at the moment without sacrificing much performance.
Some notes on potential expansions
The current design should work on any modern GPU. However could also take advantage of ReBar here in many ways. The simplest way is allocating all buffers in device local-host visible memory and perform as many updates inline as possible.
A more advanced way to make use of it would be a Linux only technique that also uses the extremely new extension
VK_EXT_map_memory_placed. This allows us to tell vkMapMemory the exact virtual address to map our buffer. So we can use this to map GPU memory, directly into our virtual address space, avoiding the need of page dirty tracking almost entirely.
The cache also makes no attempt to preserve GPU modified memory regions when a CPU write occurs to unrelated part of the same page. This means that the next time the buffer is used, part or all of the buffer will get trashed by CPU memory. This is a complex problem to solve as guest gives us little indication of when it wants to sync so it is left for later.